
티스토리 뷰
[대규모 시스템 설계 기초] 6장 : 키 - 값 저장소 설계
1. 자주 사용되는 key-value repository
- Redis, Cassandra, DynamoDB
2. 조건: application과 repository의 특성에 따라 어떤 key-value 저장소를 사용할지 달라진다.
- 어느 용도로 사용되나?
- 키-value 크기의 제약이 있는가?
- 어떤 자료구조 형태를 사용할 수 있는가?
- 어느 정도의 가용성을 가질 수 있는가?
- 어느 정도의 일관성을 가질 수 있는가?
- 어느 정도의 확장성을 가질 수 있는가?
- latency는 어느 정도까지 보장할 수 있는가?
3. 성능 개선
- 데이터 압축
- hot, cold 데이터 구분
- scale up or out
- bloom filter
4. Scale out의 조건
CAP
일관성 (consistency)
노드와 무관하게 동일한 데이터를 볼 수 있음을 의미한다. 데이터가 하나의 노드에 기록될 때마다 이 데이터는 쓰기가 '성공'으로 간주되기 전에 시스템의 다른 모든 노드로 전달, 복제되어야 한다.
가용성 (availability)
n개의 노드가 장애인 경우에도 응답할 수 있음을 의미한다. 분산 시스템의 모든 노드는 요청에 대해 유효한 응답을 리턴한다.
파티션 감내 (partition tolerance)
분산 시스템 내 노드 간의 연결이 유실되거나 일시적으로 지연된 상태이다. 이런 상태에서도 클러스터가 작동해야 함을 의미한다.

5. CAP 시스템의 종류
- CP 시스템: 일관성과 파티션 감내를 지원하는 키-값 저장소이다. 가용성을 희생한다.
- AP 시스템: 가용성과 파티션 감내를 지원하는 키-값 저장소이다. 일관성을 희생한다.
- CA 시스템: 일관성과 가용성을 지원하는 키-값 저장소이다. 네트워크 장애는 피할 수 없기 때문에 파티션 감내는 필수요소 이다. 때문에 CA 시스템은 존재하지 않는다.
6. 데이터 다중화
- 안정 해쉬: 해시 테이블 크기가 조정될 때 평균적으로 오직 k/n개의 키만 재배치하는 해시 기술이다. 여기서 k는 키의 개수이고, n은 슬롯(Slot)의 갯수이다.
- 이점
- 서버가 추가/삭제될 때 재배치되는 키의 수가 최소화된다.
- key를 균등하게 분포시킬 수 있다.


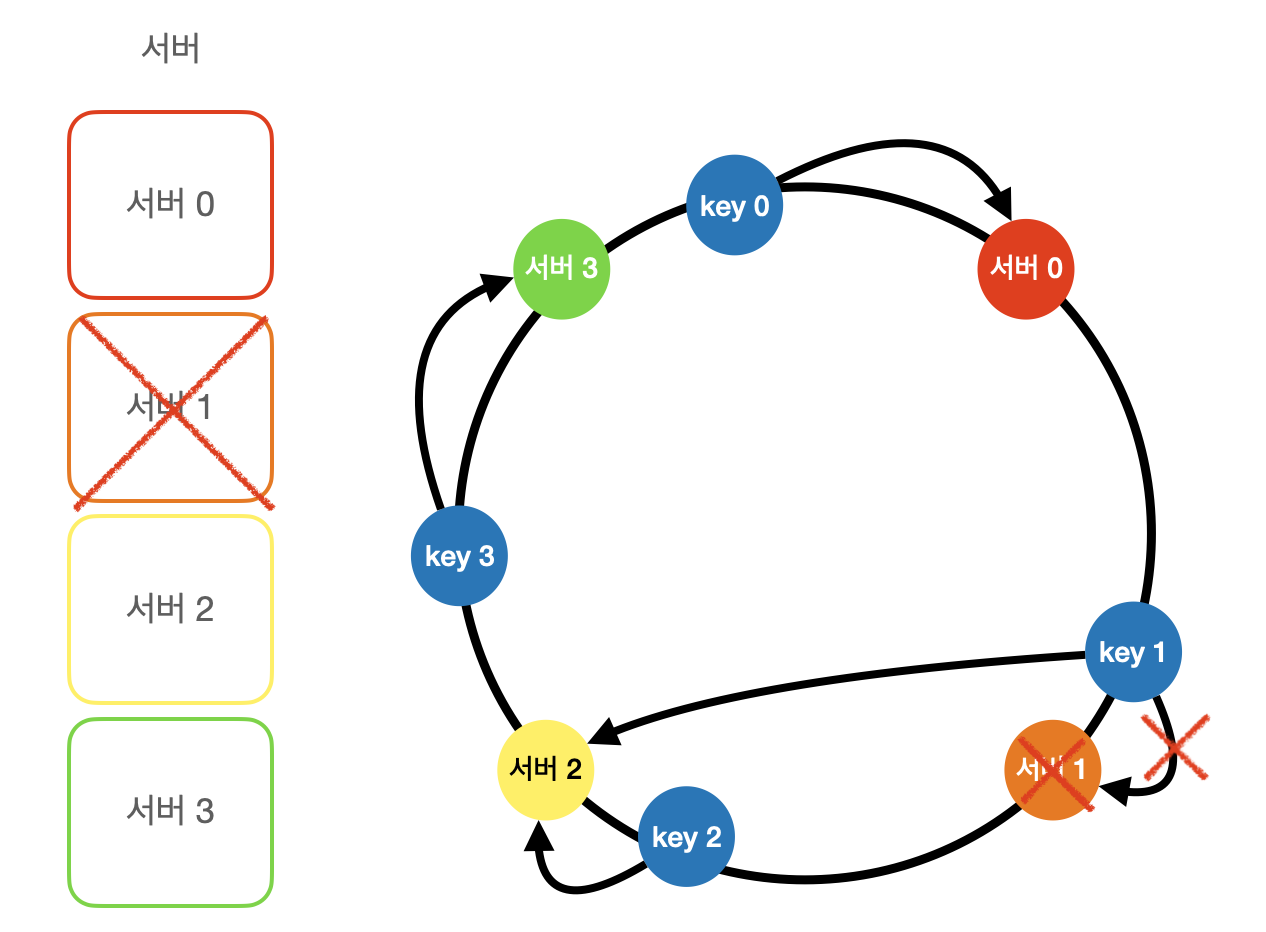
7. 데이터 일관성
- Quorum Consensus Protocol

- Write (ex: quorum 2)
1. client가 QUORUM consistency level로 write request 전송
2. coordinator node는 모든 replica node에게 write request를 전달
3. 1번 노드에서 write가 완료되어 ACK 응답
4. 3번 노드에서 write가 완료되어 ACK 응답
5. QUORUM(2)수 만큼의 replica node에서 write request가 성공했으므로 client에게 응답

- Read (ex: quorum 2)
1. client가 QUORUM consistency level로 read request 전송
2. coordinator node는 QUORUM 수 만큼의 replica node에게 read request를 전달
3. 1번 노드는 latest data를 반환
4. 5번 노드는 이전의 write request가 실패했으므로 stale data를 반환
5. coordinator node는 응답받은 두 개의 데이터의 timestamp를 비교하여 stale data를 가진 5번 node가 latest data를 가질 수 있도록 read repair 수행
6. client에게 latest data를 반환
8. 데이터 충돌 해결
- Vector Clock Versioning
벡터 시계는 D([S1, timestamp], [S2, timestamp], …와 같이 표현한다고 가정한다.
여기서 D는 데이터이고, Si는 서버 번호 이다.
만일 데이터 D를 서버 Si에 기록하면, 시스템은 아래 작업 가운데 하나를 수행하여야 한다.
- [Si, vi]가 있으면 vi를 증가시킨다.
- 그렇지 않으면 새 항목 [Si, 1]를 만든다.

9. 장애 감지
- Gossip Protocal: 프로토콜을 통해 각 노드는 클러스터의 다른 노드에 대한 상태 정보(예: 도달 가능한 노드, 담당하는 키 범위 등)를 추적할 수 있다. (기본적으로 해시 링의 복사본). 노드는 동기화 상태를 유지하기 위해 상태 정보를 공유한다. 가십 프로토콜은 노드가 자신과 자신이 알고 있는 다른 노드에 대한 상태 정보를 주기적으로 교환하는 P2P 통신 메커니즘이다. 각 노드는 자신 및 다른 노드에 대한 상태 정보를 다른 임의의 노드와 교환하기 위해 1초마다 가십 라운드를 시작한다. 이는 모든 새로운 이벤트가 결국 시스템을 통해 전파되고 모든 노드가 클러스터의 다른 모든 노드에 대해 빠르게 학습함을 의미한다.
- Seed Node: 가십 프로토콜은 특정 시나리오에서 클러스터의 논리적 파티션을 초래할 수 있다. 관리자는 노드 A를 링에 조인한 다음 노드 B를 링에 조인한다. 노드 A와 B자신을 링의 일부로 생각하지만 둘 다 서로를 즉시 인식하지 못한다. 이러한 논리 파티션을 방지하기 위해 일부 분산 시스템에서는 시드 노드 개념을 사용한다. 시드 노드는 완전히 작동하는 노드이며 정적 구성 또는 구성 서비스에서 얻을 수 있다. 이런식으로 모든 노드는 시드 노드를 인식합니다. 각 노드는 구성원 변경을 조정하기 위해 가십 프로토콜을 통해 시드 노드와 통신한다. 따라서 논리적 파티션은 가능성이 거의 없다.

10. Bloom filter
- 긍정 오류(false positive) 가능성이 O
- 부정 오류(false negative) 가능성이 X
-> true이면 존재할 가능성이 있다.
-> false이면 확실히 존재하지 않는다.
'Programming > Others' 카테고리의 다른 글
| [대규모 시스템 설계 기초] 1장 (0) | 2022.06.05 |
|---|---|
| UTC, GMT 차이 (1) | 2022.02.04 |
| X-Forwarded-For (0) | 2019.08.30 |
| 정규식 (0) | 2017.05.16 |
- Total
- Today
- Yesterday
- Property
- docker
- Join Table
- Registrar
- RetryTemplate
- Query DSL
- java EqualsAndHashCode
- Mapping
- spring spel
- Charles proxy
- Spring JDBC Template
- java generic
- Discriminate Mapping
- java Equals
- SmartLifecycle
- Embedded Mapping
- Typesafe Config
- Spring Registrar
- Spring
- Akka
- DI
- 복합키 Mapping
- Criteria
- JPA
- @Primary
- guava
- scikit-learn
- Embeddable Mapping
- Sprint RetryTemplate
- JPA Criteria
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |